Over the past two years I have done a bunch of structural bioinformatic work, resulting in the paper Ligand binding remodels protein side chain conformational heterogeneity. And I made A LOT of mistakes.
Below are many of the lessons, guidelines, and pitfalls for a structural bioinformatic analysis. While many of the principles below are specifically tailored to a paired analysis (such as apo versus holo or peptide bound versus small molecule bound), these guidelines can help with any structural bioinformatics project.
For specific suggestions, I have the code I created linked at the bottom of each section. This code is built on bash, python, Phenix/cctbx, and qFit. The code should be easily adaptable to other projects/inquiries. If there are any questions, feel free to contact me.
Define your selection criteria early.
Before you start downloading structures, you need to decide what structures you would like to highlight. Some of these items can be subsetted using the PDB advanced selection criteria, including:
- Method of structure (X-ray, CryoEM, NMR, Neutron, ect)
- Resolution
- Cryo or Room Temperature
- Size of the protein
- Type of ligands
- Single or multidomain proteins
You may also want to cross check these structures with external databases (ChemBL, Uniprot, ect). You can do much of this work on the PDB website in their advanced search section.
Once you get a list of structures with your initial criteria, you can parse the header of the PDB or get other statistics of PDB/density file from the MTZ file with a program like phenix.mtz_dump.
This is the stage where you will start creating pairs of structures. Some criteria you will want to think of at this stage include:
Unit cell dimensions and angles
Space group
Sequence (get this from the PDB and not from another database to know which residues were actually resolved in the structure).
Ligand types/crystallographic additives (how much overlap do you want between the paired structures)
Experimental methods such as crystallographic conditions (this will be tricker but may be important and worth it to go through headers manually).
At this stage, I suggest keeping duplicate pairs (ie if you have multiple apo or wildtype proteins for each holo or mutant proteins). Many structures will be thrown out downstream and it can be helpful to have ‘back ups’.
Here is a pipeline you can use to select the PDBs to move forward in your analysis.
Re-refine structures.
The PDB has a lot of structures refined with many different software packages and versions. To ensure that you are comparing apples to apples, pick one refinement software version and re-refine all of your structures.
The software that I used was phenix.refine.
Unless you know exactly how you want to refine your structures, spend some time with ~15 structures and play around with refinement strategies. Some things to think about:
Do you want different resolution cutoffs to have different refinement strategies?
Are you going to refine anisotropically or with hydrogens?
How are different refinement strategies impacting the R-free or R-gap of structures?
Once you have a refinement script you are happy to test your refinement script with ~50 PDBs, find errors and adjust from there. As the PDB files you are feeding your refinement strategy may be labeled in many different ways, you are likely going to have to build in flags as well as if statements to refine the structures.
If 80% of your structures are re-refined, move on. Send bugs to the respective software groups, and accept your losses (trust me, they are not worth it!).
Here is an example re-refinement pipeline that works with Phenix version 1.19.
Here is a pipeline that will re-refine your structures, run qFit, and then refine your qFit structure.
Quality control of structures.
The first, and easiest part of quality control of structures has to do with refinement metrics.
Are you decreasing the R-free or R-gap? This can be extracted through refinement log files or running additional analysis.
Are there any clashes in the structure?
Are there Ramachandran outliers?
With pairs, you want to assess how well they align together in 3D. Aligning them is a beast in and of itself. Due to structures with the same sequence having different chain ids or residue numbers, we will need to match those up as all downstream analyses will rely on this.
There are many different methods to align structures, but I landed with pymol, alpha carbon align. This did not work well for 100% of the paired structures I had but it is what worked for the majority of them.
I then required all chains start with residue 1. Then, as I was working with paired structures, I based all holo structures off of apo structures. Therefore, I reassigned the closest geometric chain in the holo to the chain in the apo.
Some additional criteria you will want to think about in this stage include:
How well do the backbones of structures line up? This can be assessed by alpha carbon RMSD between the structures. While some analyses may want to keep large changes, others may want to throw them out.
How much do the ligands overlap between the structures?
Here is a pipeline that will extract and compare R-values, align your pairs, and spit out alpha RMSD and ligand overlap between the pairs.
Analysis of structures
Now we get to the fun stuff!
Before we can run any analysis, you need to think about how you want to extract information from the structures. Are you going to do it based on chain and residue numbering or based on location. I choose the former as it is easier downstream. However, this required me to reassign the chain and residue numbers for many structures (see above).
The other thing to think about when comparing structures is if there are duplicates. In my case, I had multiple holo assigned to multiple apo. Therefore in the analysis, it was important to keep track of not just the PDB, but also the PDB’s matched pair.
Finally, you also need to consider how you are going to look at certain sections of the PDB. For example, I wanted to examine binding site residues. But my criteria (any residue heavy atom within 5A of any ligand heavy atom) sometimes gave me one or two different residues in the holo or apo depending on how much those residues moved. I decided to look at the union of those two lists, but you could also look at the intersection of those two lists.
Here are a bunch of analyses that I ran on my pairs or individual models.
Quality control of the analysis
For almost every single analysis I did, I would plot the result and have a few outrageous outliers. This was always a clue of something I coded wrong in the analysis, or something incorrect about the labeling of the PDBs.
When looking at the result of your analysis, always look at the minimum and maximum values on both an individual basis (ie if you are looking at some sort of residue metric), as well as on a structure basis. Take at least the top and bottom five metric values and go through checking for the following:
Is residue 1, chain A of structure 1 within your RMSD cutoff of residue 1, chain A of structure 2?
If you manually calculate the metric you are measuring, is it matching what your code says?
Look at the structure in Pymol or Chimera. Does the numerical value of the metric line up with what you are visualizing?
Repeat this process until you can visually/biologically explain at least the top and bottom five metric values.
Background
A group of scientists within the Fraser lab have begun a journal club centered around issues of diversity, equity, inclusion, and justice within academia, specifically in the biological sciences.
Our goal is to provide an environment for continued learning, critical discussion, and brainstorming action items that individuals and labs can implement. Our discussions and proposed interventions reflect our own opinions based on our personal identities and lived experiences, and may differ from the identities and experiences of others. We will recap our discussions and proposed action items through a series of blog posts, and encourage readers to directly engage with DEIJ practitioners and their scholarship to improve your environment.
Article: Addressing racism through ownership. Dutt, K. DOI: 10.1038/s41561-021-00688-2
Article: Black Scientists Are Not the Door to Diversity. Hayes, CA. DOI: 10.1021/acschemneuro.1c00375
Article: The Burden of Service for Faculty of Color to Achieve Diversity and Inclusion: The Minority Tax. Trejo J. DOI: 10.1091/mbc.E20-08-0567
Summary: Marginalized people are expected to dismantle oppressive systems that actively disenfranchise them, an expectation known as the Minority Tax. How does this tax impact people at different stages of their career, and how do we combat this expectation?
Key Points:
- Successful DEIJ work takes teamwork.
- There is a lack of respect for DEIJ work.
- This is most obvious in the deliberate exclusion of DEI work from traditional metrics of professional progress, such as promotion and funding.
- Universities are often recognized and praised for the contributions of individuals to DEIJ work.
- There is a lack of support for DEIJ work.
- This work is rarely done by an expert. Instead, those with lived experiences are often tasked with developing and implementing DEI efforts. This model results in mixed outcomes while allowing universities to claim they support DEIJ initiatives.
Open Questions
- How do we get more people involved in DEIJ work?
- What do you do with people who are not interested in contributing to DEIJ?
- How do we track and reward DEIJ effort among academic personnel?
- How do we evaluate the impact of diversity efforts in academia?
- Is it appropriate for basic scientists to create and lead DEIJ efforts?
Proposed Action Items:
- Estimate how much time you are spending on DEIJ work compared to others. Take note of who shows up to meetings, comes up with ideas, and executes those ideas.
- Increase the importance of service work, specifically DEIJ work, in tenure and promotion decisions.
- Provide material resources, such as hiring full-time staff or providing money for consultants, to implement DEIJ projects or initiatives.
Background
A group of scientists within the Fraser lab have begun a journal club centered around issues of diversity, equity, inclusion, and justice within academia, specifically in the biological sciences.
Our goal is to provide an environment for continued learning, critical discussion, and brainstorming action items that individuals and labs can implement. Our discussions and proposed interventions reflect our own opinions based on our personal identities and lived experiences, and may differ from the identities and experiences of others. We will recap our discussions and proposed action items through a series of blog posts, and encourage readers to directly engage with DEIJ practitioners and their scholarship to improve your environment.
Article: The limits of settlers’ territorial acknowledgments. Asher L, Curnow J & Davis A (2018) DOI: 10.1080/03626784.2018.1468211
Summary: There has been an increase in the performance of land acknowledgments by non-Indigenous people in non-Indigenous, primarily academic settler, spaces. This article examines what purpose do these land acknowledgments serve, who are they for, and can land acknowledgments performed by settlers be improved to better reflect the original intentions of Indigenous people who created this practice?
Key Points:
- Settlers perform land acknowledgments as a means of combating the erasure of Indigenous people.
- The pedagogical intention has been to combat erasure and force settlers to grapple with our positionality.
- In becoming standardized and mainstream, it is reduced to a “mundane “box-ticking” exercise, easily ignored and void of learning opportunities.”
- Settler moves to innocence are those strategies or positionings that attempt to relieve the settler of feelings of guilt or responsibility without giving up land or power or privilege, without having to change much at all.
- The practice needs to be improved to avoid becoming rote and normalized.
Open Questions:
- What pedagogical work do territorial acknowledgments accomplish in settler spaces?
- What do people learn from a territorial acknowledgment and does it serve any decolonial purpose?
- Are territorial acknowledgments productive in disrupting avoidance mechanisms and pushing settlers towards decolonial solidarity?
Proposed Action Items:
- Begin including an intentional and well-researched land acknowledgment in your presentations.
- Include specific examples of how settlers can contribute to decolonial efforts.
Background
The PanDDA algorithm is a super useful tool for detecting low occupancy ligands in electron density maps obtained by X-ray diffraction. Low occupancy ligands are frequently encountered in fragment screening campaigns, and PanDDA can greatly increase the hit rate of a fragment screen and therefore increase the number of starting points available for fragment-based ligand discovery. We’ve used PanDDA for fragment screens against the PTP1B phosphatase and the NSP3 macrodomain from SARS-CoV-2. After modeling ligands, the data are deposited in the PDB. Data includes the atomic coordinates, the structure factor intensities, the map coefficients after final refinement with the ligand, and the PanDDA event map coefficients. The structure factor intensities and the map coefficients as separate data blocks in a single CIF.
The problems
There are two problems with looking at this data after downloading it from the PDB. The first problem is that because of the low occupancies of ligands, maps based on the structure factor intensities or the map coefficients after final refinement with the partial occupancy ligand often do not contain convincing electron density evidence for the bound ligand. That evidence is best found in the PanDDA map.
The second problem is that CIFs with multiple data blocks can be tricky to convert into MTZ files for visualization in COOT. From my experience, running phenix.cif_as_mtz will lead to the correct conversion of the map coefficients from the refined data, however, the PanDDA event map coefficients may not be converted. The structure factors encoding the PanDDA event map are based on the real space analysis and in space group P1, not the symmetry of the corresponding PDB file.
The solution
We split the CIF containing the three data blocks into separate CIFs. Actually, it’s fine just to extract the PanDDA event map block into one CIF, and move the original and refined data in another. Then run phenix.cif_as_mtz on the separate CIFs, with the correct symmetry flags specified, to convert them into MTZ files.
The extract_pandda.sh script does this for you. Download the coordinates and structure factor file from the Protein Data Bank (xxxx.pdb and xxxx-sf.cif files, where xxxx is the four letter PDB code) and move them to a working directory. On the command line, run ./extract_pandda.sh xxxx-sf.cif SG (where SG is the space group of the crystal). The script will split the CIF into two separate CIFs, containing the refined and original data (xxxx-sf_data.cif) or the PanDDA event map (xxxx-sf_pandda.cif). The script then runs phenix.cif_as_mtz and converts the CIFs to MTZs for visualization in COOT.
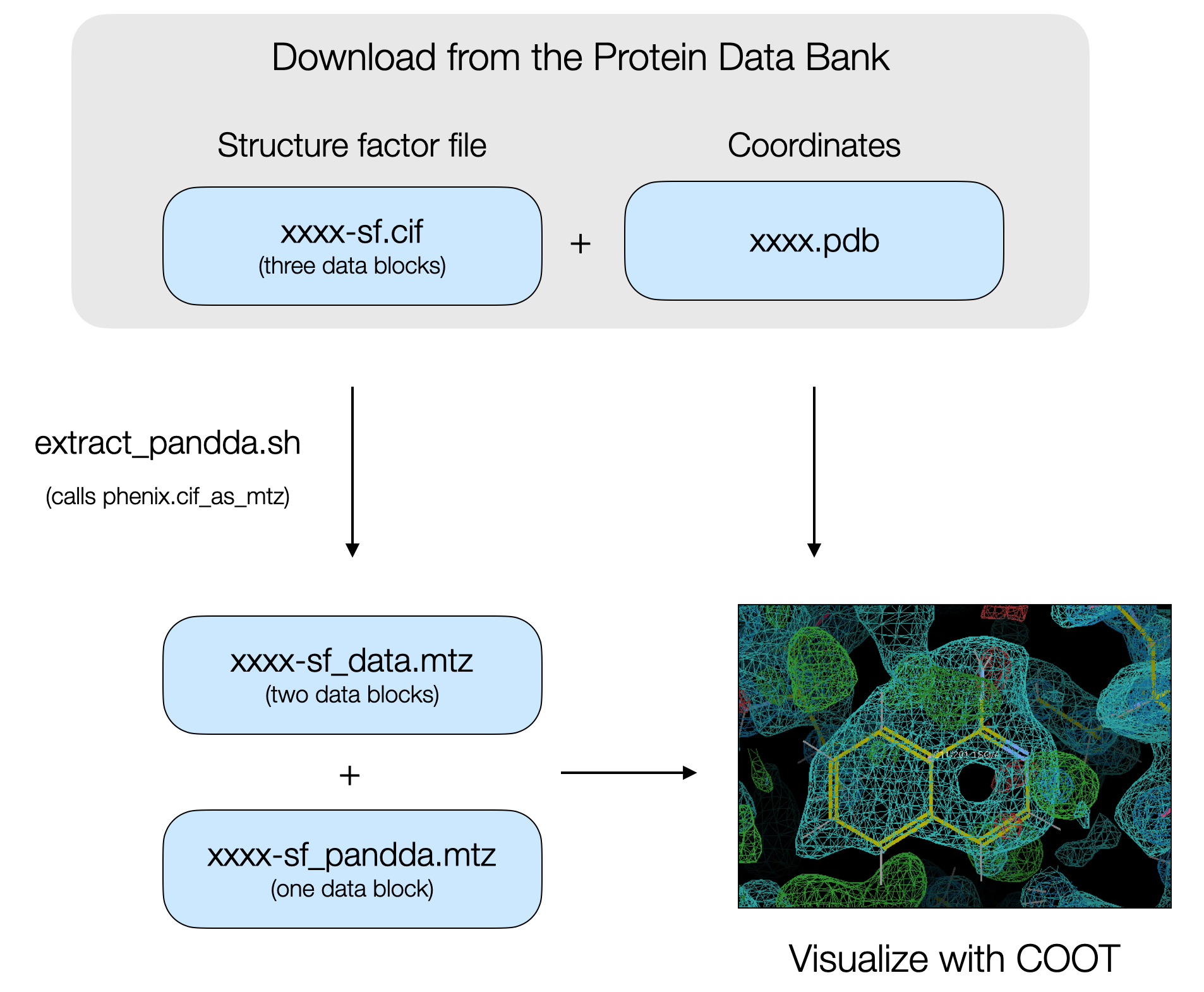
Caveats
The script needs the Phenix version dev-4338 to run, available here.
Data blocks need to be named as follows in the CIF (where xxxx is the PDB code):
- Data from final refinement with ligand: data_rxxxxsf
- PanDDA event map: data_rxxxxAsf
- Original data: data_rxxxxBsf
One of the best things we can give each other as colleagues is our time and attention.
Therefore, to receive pertinent advice and make the most out of 1:1 and subgroup meetings, it is imperative to effectively communicate our immediate goals and expectations.
I would consider myself a goal-oriented individual, so concretely breaking down overarching goals into smaller to-do items helps me not only outline what needs to be done to get to the finish line, but also allows me to schedule and prioritize my efforts.
As a side-effect, this also helps me better communicate, having already reflected and planned out what I hope to accomplish in a given timeline.
I have found the best way to prepare for 1:1 or subgroup meetings is by using the usual and brilliantly simple slideshow, as having a visual aid grounds the conversation.
When sitting down to prepare any 1:1 or subgroup meeting, I first ask myself a few questions:
- What is my biggest current goal?
- What have I done to progress towards accomplishing that goal?
- What do I have left to do?
- What comes next?
- Is there anything else I’d like to talk about?
In thinking about these questions, I try to keep it fairly discrete.
As a graduate student my obvious biggest goal is to graduate, but my biggest goal of the month might be to make some mutants for an assay, so I stay focused on that and begin outlining my thoughts on the first slide itself.
Since we meet about twice a month for subgroup meetings, I keep the slides focused on monthly goals.
However, for 1:1 meetings the outlined goals can be more overarching if I think I need perspective on the project as a whole, or if meeting 1:1 on a weekly basis I’ll focus the discussion on plans for the week.
Once I have my talking points outlined, I then proceed to make the rest of the slides.
At this stage it becomes like preparing an extremely condensed group meeting, where the focus is on showing the experimental workflow and data I have collected, or simply in bullet points listing the things I have accomplished or have yet to do.
One thing I place great time in when preparing for the meeting are the questions “what comes next?” and “is there anything else I’d like to talk about?” mainly because these might be less tangible than let’s say cloning a mutant.
These are the questions that are the most reflective about the present and future.
For instance, what will making this protein mutant allow me to do next and why is that important for my project?
Clearly explaining how and why your goals are important for your project, career, etc. is the crux of a productive meeting.
If the slides have been thoughtfully prepared, it should then be pretty easy to discuss your plans, show your productivity, and manage your time in the meeting.
Everything is at your fingertips, and if you forget or run out of time to discuss a topic, it’s there in writing to discuss later on Slack, in passing, or whatever you find most appropriate.
Remember, 1:1 and subgroup meetings are your time! It’s your time to get feedback, advice, vent about why things aren’t working, express happiness about things that are working, ask for support, brainstorm, and map out next steps!
Be thoughtful and use your time wisely.
Here’s an example of one of my own subgroup meeting slides.